Evaluate Rag Pipelines
How to Evaluate RAG Pipelines: A Simple Guide to Getting It Right
🤷♀️ Evaluating RAG pipelines is like building a house: you wouldn’t start decorating before ensuring the foundation is strong, would you? Before you add all the fancy features, you need to make sure your evaluation setup is solid. It’s crucial but often overlooked. That’s why I’ve put together this quick guide to help you navigate the process.
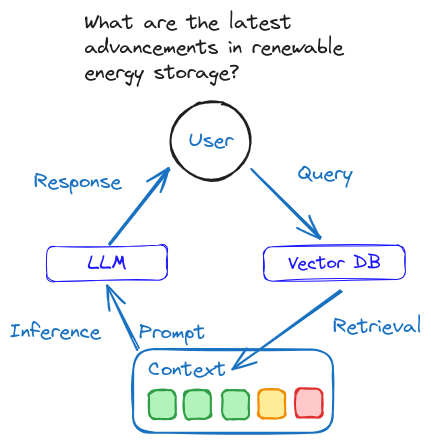
I’ve broken it down into two main parts because, just like a good conversation, RAG pipelines involve both listening and responding. In tech terms, that means retrieving information and then generating a response. Each part needs its own set of evaluation metrics.
📖 Retrieval Dimensions: The Listening Part
-
Context Precision: Think of this as how well you’re tuning in to the conversation. Are you picking up the most important details first, or are you getting sidetracked? It’s about prioritizing the most relevant bits of information.
-
Context Recall: This is your memory check. Did you remember all the key points of the conversation? It’s about making sure you retrieve information that closely matches what was asked.
-
Context Relevance: Imagine you’re at a party, and someone asks about your favorite book. Do you respond with something on-topic, or do you start talking about your love for pizza? This dimension checks whether the retrieved context is actually relevant to the question.
-
Context Entity Recall: Are you getting the names and places right? This checks whether all the important entities (like people, places, or things) are correctly recalled from your memory bank.
-
Noise Robustness: Ever had someone throw random facts into a conversation, making it hard to follow? This dimension evaluates how well the model can handle irrelevant or distracting information.
📖 Generation Dimensions: The Responding Part
-
Faithfulness: This is about trustworthiness. When you generate a response, is it factually correct based on the information you retrieved? It’s like making sure you’re not just making stuff up.
-
Answer Relevance: Imagine if someone asked you for advice and you gave them a completely unrelated answer. Not very helpful, right? This checks if the generated response actually answers the question.
-
Information Integration: This is like being a good storyteller. Can you combine different pieces of information into a coherent and useful answer?
-
Counterfactual Robustness: Sometimes, people get things wrong. This dimension checks if the model can spot and correct these inaccuracies, making sure it doesn’t fall for misinformation.
-
Negative Rejection: Sometimes, the best response is no response. This measures if the model can resist the urge to answer when it doesn’t have the right information.
Why All This Matters
😎 Understanding these dimensions is like having a roadmap for evaluating your RAG pipeline. Without them, you’re just guessing whether it’s working well or not. Many frameworks already include these dimensions, so before you dive into your project, make sure to check them out. They’re your toolkit for building a robust and reliable system.
Metrics & Frameworks
Just like how a chef needs the right tools to create a great dish, evaluating RAG pipelines requires the right metrics and frameworks. Here’s a quick rundown of what’s typically used:
- Metrics: Accuracy, Precision, Recall, Cosine Similarity, BLEU, ROUGE, and more.
- Frameworks: RAGas, TruLens, ARES, DeepEval, and others.
The image guide I’ve shared covers these in more detail, so be sure to check it out. Whether you’re new to evaluating RAG pipelines or just need a refresher, these dimensions will help you ensure your model is both a good listener and a great responder.
So, before you add those fancy features, make sure your foundation is solid. It’s the key to a successful and reliable RAG pipeline.
Happy building! 🏗️